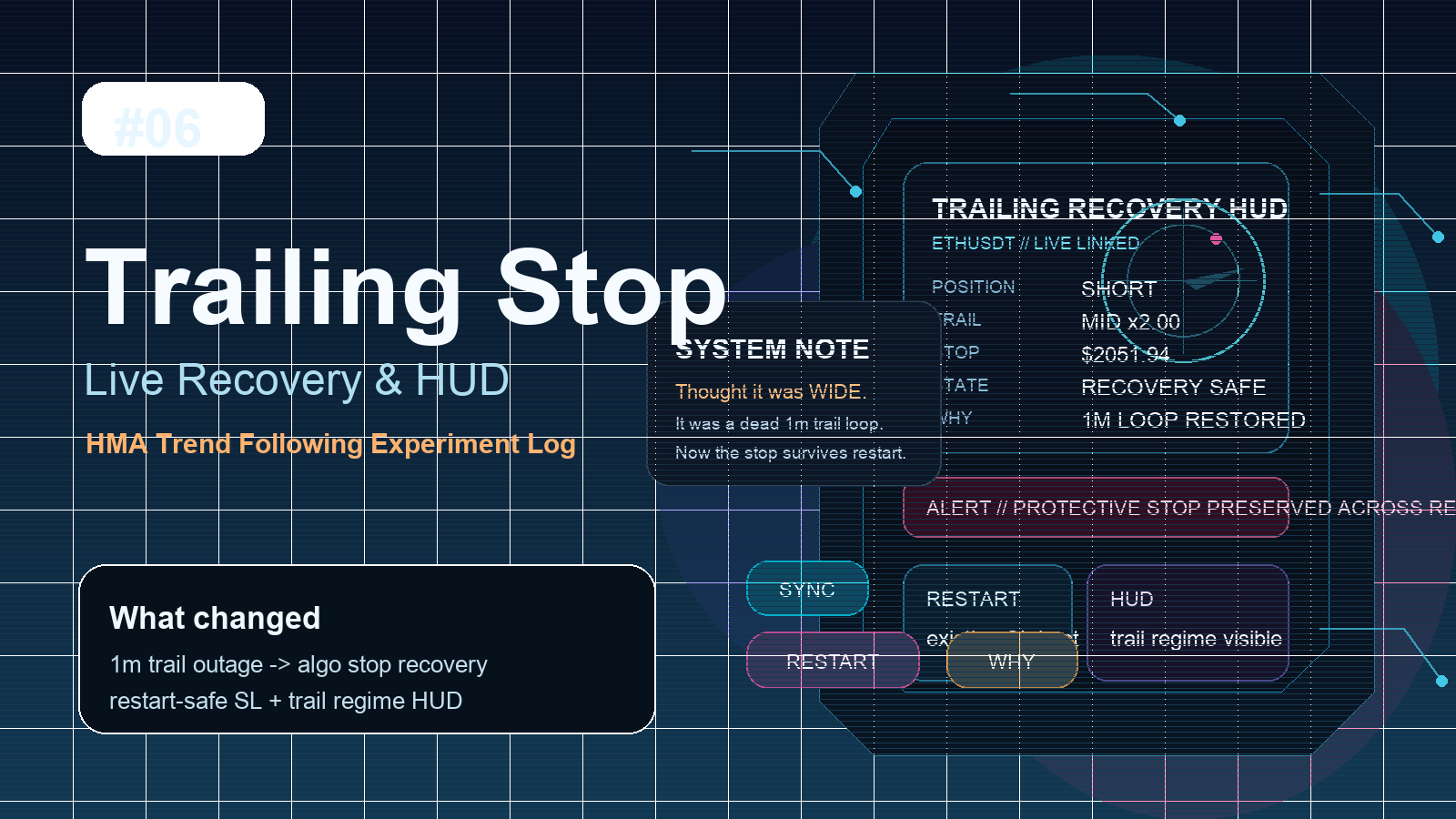
#06 트레일링 스탑이 실제로 작동하지 않던 밤, 그리고 라이브 복구 기록
이번 기록은 작은 오해 하나에서 시작됐다. 포지션은 이미 수익 구간에 들어가 있었고, 화면에 보이는 손익도 나쁘지 않았다. 그런데 이상하게도 손절 라인이 내가 기대한 만큼 좁혀지지 않는 것처럼 보였다. 처음에는 이유를 단순하게 생각했다. 아마 slope가 강해서 adaptive trailing이 아직 wide 구간에 머물고 있겠지. 그 정도의 해석이면 충분하다고 믿고 지나갈 수도 있었다.
하지만 로그를 열어보는 순간, 이야기는 완전히 다른 방향으로 흘렀다. 문제는 wide가 아니었다. 1분봉 트레일링 루프가 아예 작동하지 않고 있었다. 내가 보고 있던 것은 느리게 움직이는 트레일링이 아니라, 사실상 멈춰 있는 보호 로직이었다.
운영 중인 봇에서 이런 종류의 오해는 생각보다 위험하다. 시스템이 보기에 그럴듯하게 살아 있는 것과, 실제로 의도한 보호 기능이 작동하고 있는 것은 전혀 다른 문제이기 때문이다. 이번 작업은 그 차이를 하나씩 밝혀내고 다시 복구하는 과정이었다.
처음 질문은 아주 단순했다
출발점은 “지금 SL이 왜 더 좁혀지지 않지?”라는 질문이었다. 숫자만 보면 그럴듯한 설명이 가능했다. 강한 추세 구간이면 wide 배수가 적용되고, 그러면 SL이 빠르게 당겨지지 않을 수 있다. 그래서 처음엔 전략이 의도대로 보수적으로 움직이고 있는 줄 알았다.
하지만 로그는 냉정했다. 1분 트레일 루프는 매 분마다 아래 에러를 남기고 있었다.
1m Trail: OHLCV 조회 실패 — 'BinanceClient' object has no attribute 'fetch_ohlcv'
즉, 전략 판단이 느린 것이 아니라 데이터를 읽지 못하고 있었던 것이다. 그 순간부터 이번 이슈는 단순한 파라미터 해석이 아니라, 라이브 보호 체계 전체를 다시 확인해야 하는 문제로 바뀌었다.
하나를 고치면 다른 것이 드러났다
보통 운영 이슈는 원인을 하나 찾고 끝나지 않는다. 첫 번째 오류를 고치면, 그 아래 눌려 있던 두 번째와 세 번째 오류가 차례로 얼굴을 내민다. 이번에도 정확히 그 흐름이었다.
1. 1분봉 트레일링 루프가 실제로 죽어 있었다
가장 먼저 한 일은 BinanceClient에 fetch_ohlcv() 래퍼를 추가하는 것이었다. 엔진은 1분봉 보호 루프에서 이 메서드를 호출하고 있었지만, 클라이언트에는 그 메서드가 아예 없었다. 겉으로는 트레일링이 돌아가는 것처럼 보여도, 실제로는 1분봉 데이터를 한 번도 읽지 못하고 있었던 셈이다.
이 수정 이후에야 1분 트레일 루프가 다시 살아났다. 하지만 여기서 끝나지 않았다.
2. 보호 주문이 거래소에 실제로 기대한 방식으로 걸리지 않고 있었다
트레일 루프가 살아난 뒤 다음으로 확인한 건, 서버사이드 SL 주문이 정말 바이낸스에 남아 있는가였다. 여기서 또 하나의 문제가 드러났다. 기존 구현은 보호 주문을 일반 주문 경로처럼 다루고 있었지만, 실제 바이낸스 선물 쪽에서는 이 보호성 조건 주문을 Algo Order API로 봐야 하는 구조였다.
그래서 수정 범위는 자연스럽게 넓어졌다.
- SL / TP 생성
- open orders 조회
- cancel / fetch 경로
- 내부 주문 ID 추적 형식
보호 주문 레이어 전체를 Algo API 기준으로 다시 맞췄다. 그제야 “로그에는 있다고 나오는데 거래소엔 없는 것 같은” 모호한 상태들이 정리되기 시작했다.
3. precision과 응답 형식 문제도 같이 손봐야 했다
문제는 API 라우팅만 바꾼다고 끝나지 않았다. 다음엔 -1111 Precision is over the maximum defined for this asset 에러가 올라왔다. 가격과 수량을 심볼 precision에 맞게 정규화하지 않고 넘기고 있었기 때문이다.
거기서 한 걸음 더 들어가니, 응답 shape도 예상과 완전히 같지 않았다. 어떤 곳은 dict를 기대하고 있었지만 실제로는 list가 왔다. 결국 precision 정규화와 응답 정규화 레이어까지 같이 보강해야 했다. 작은 버그를 하나 고치는 과정이 아니라, 보호 주문 파이프라인 전체를 실제 거래소 응답에 맞게 다시 만드는 작업으로 커진 셈이다.
복구가 끝난 줄 알았는데, 다시 한 번 위험한 장면이 나왔다
실서버 반영 후 한동안은 문제가 정리된 것처럼 보였다. 1분 트레일 루프도 살아 있었고, 보호 주문도 다시 잡혔다. 그런데 여기서 또 하나의 중요한 질문이 나왔다. /restart를 하면 이전 고점/저점 기억은 어떻게 되는가.
이 질문이 중요했던 이유는, 실전에서는 재시작이 종종 필요하기 때문이다. 에러 복구, 상태 정리, 배포 후 반영 같은 순간에 재시작은 충분히 일어난다. 그런데 재시작 때문에 기존보다 더 불리한 SL이 새로 깔린다면, 그건 복구가 아니라 새로운 리스크다.
실제로 확인해보니 그 우려는 맞았다. 재시작 후 포지션 복구 시점에 max_fav_move가 초기화되고, 엔진은 현재 ATR 기준의 초기 SL을 다시 계산하고 있었다. 그 결과, 이미 더 유리한 위치에 있던 stop이 재시작 한 번으로 더 넓어질 수 있었다.
이 문제는 기능적으로는 작아 보여도, 운영 감각으로 보면 꽤 위험한 종류였다. 그래서 복잡한 완전 복구 대신, 먼저 최소 안전 패치를 넣었다.
- 재시작/복구 시 거래소에 이미 살아 있는 보호 SL을 먼저 읽는다.
- 그 SL이 현재 포지션에 더 유리하면 그대로 인계한다.
- 새 ATR 기반 초기 SL은 기존보다 더 유리할 때만 교체한다.
이 패치 이후 로그에는 아래처럼 아주 중요한 문장이 남기 시작했다.
복구 시 기존 SL 인계: 2051.94복구 시 기존 SL 유지: 2051.94 (init=2060.42)
이건 이번 세션에서 가장 마음이 놓였던 순간 중 하나였다. 이제 재시작은 더 이상 stop을 불리하게 넓히는 동작이 아니게 됐다.
운영 도구도 같이 바뀌었다
이번 작업은 단순히 오류를 고치는 데서 끝나지 않았다. 오히려 뒤로 갈수록 운영자가 시스템을 더 잘 이해할 수 있게 만드는 쪽으로 자연스럽게 확장됐다.
1. HUD는 이제 상태만이 아니라 해석도 같이 보여준다
이전에는 HUD에 현재 가격, SL, slope, deadzone이 따로 보였지만, 정작 중요한 질문인 “그래서 지금 trailing이 wide인가, mid인가, tight인가”는 사용자가 머릿속에서 계산해야 했다. 이번에는 그 부분을 명시적으로 드러내기로 했다.
그래서 이제 HUD에는 아래 같은 정보가 함께 붙는다.
Trail: WIDE x4.50Trail: MID x2.00Trail: TIGHT x0.30
상태판에는 S/D 정보까지 같이 붙어서, “지금 stop이 왜 이렇게 움직이는가”를 훨씬 빠르게 해석할 수 있다. 이건 단순히 보기 좋은 장식이 아니라, 운영자의 추론 부담을 줄이는 작은 인터페이스 개선이다.
2. 재시작도 텔레그램 운영 흐름 안으로 넣었다
/restart 명령과 HUD 버튼도 이번에 같이 정리했다. 시스템이 살아 있고 텔레그램이 응답하는 상황이라면, 터미널 없이도 재기동을 요청할 수 있게 한 것이다. 물론 이 기능은 함부로 누르는 버튼이 아니라, 현재 포지션과 보호 주문 상태를 이해한 뒤에 조심스럽게 써야 하는 버튼이다.
하지만 중요한 건, 이제 운영 중 “복구를 위해 꼭 터미널이 있어야만 하는” 순간을 조금 줄였다는 점이다. 실제로 라이브 봇 운영은 기능보다도, 복구 경로가 얼마나 명확한가가 더 중요할 때가 많다.
배포 과정도 다시 손봤다
이 세션에서 드러난 문제는 봇 코드만의 문제가 아니었다. 배포 스크립트도 같이 손을 봐야 했다. 이전엔 rsync --delete 때문에 서버 전용 파일이 지워질 위험이 있었고, 실제로 한 번은 .env, .venv, 런타임 상태 파일들을 복구해야 하는 상황까지 갔다.
그래서 deploy.sh에도 보호 규칙을 추가했다.
.env.venv/.git/config/credentials.jsonconfig/token.jsondata/risk_state.json
지금은 코드 배포와 서버 런타임 상태가 조금 더 분리된 상태다. 실전 시스템에서 이런 차이는 꽤 크다. 문제는 코드보다, 코드 외부의 운영 상태에서 더 자주 터지기 때문이다.
이번 세션이 남긴 것
이번 작업은 처음엔 트레일링 스탑 하나를 확인하는 일처럼 보였다. 하지만 끝내고 보니, 실제로 정리한 건 훨씬 넓었다.
- 작동한다고 믿고 있는 것과, 실제로 작동하는 것은 다르다.
로그를 보기 전까지는wide해석만으로도 설명이 가능해 보였다. 하지만 실제 문제는 1분 트레일이 죽어 있었다는 점이었다. - 보호 주문은 전략 일부가 아니라 운영 핵심이다.
SL API, precision, 응답 정규화, 재시작 복구 모두 결국 같은 결론으로 이어졌다. - 좋은 HUD는 숫자를 많이 보여주는 화면이 아니라, 해석을 줄여주는 화면이다.
Trail regime 표시는 아주 작지만, 실제 운영에선 꽤 큰 차이를 만든다. - 복구 경로는 미리 다듬어둬야 한다.
재시작, sync, 배포, 상태 복구가 모두 안전하게 이어질 때 비로소 라이브 시스템이 된다.
마무리
가끔은 시스템이 조용해서 더 위험하다. 에러가 한 화면을 가득 채우는 날보다, “아마 잘 돌아가고 있겠지”라고 믿게 만드는 밤이 오히려 더 긴장된다. 이번 세션은 바로 그런 종류의 밤이었다.
다행히 이번엔 그 조용함을 그냥 지나치지 않았다. 트레일 루프를 살리고, 보호 주문을 다시 세우고, 재시작이 stop을 악화시키지 않게 만들고, 마지막에는 운영 HUD가 지금 상태를 더 솔직하게 말하도록 고쳤다. 아주 화려한 기능이 늘어난 것은 아니지만, 시스템은 분명히 더 믿을 수 있는 쪽으로 움직였다.
다음에도 비슷한 순간은 또 올 것이다. 하지만 적어도 이번 이후로는, “왜 SL이 안 움직이지?”라는 질문 앞에서 조금 더 빨리 진실에 도달할 수 있을 것 같다. 때로는 그 한 걸음이 수익보다 더 중요하다.